老刘测评
老刘测评




基本概念流式查询指的是查询成功后不是返回一个集合而是返回一个迭代器,应用每次从迭代器取一条查询结果。流式查询的好处是能够降低内存使用。如果没有流式查询,我们想要从数据库取 1000 万条记录而又没有足够的内存时,就不得不分页查询,而分页查询效率取决于表设计,如果设计的不好,就无法执行高效的分页查询。因此流式查询是一个数据库访问框架必须具备的功能。流式查询的过程当中,数据库连接是保持打开状态的,因此要注意的是:执行一个流式查询后,数据库访问框架就不负责关闭数据库连接了,需要应用在取完数据后自己关闭。
MyBatis 流式查询接口
MyBatis 提供了一个叫
org.apache.ibatis.cursor.Cursor的接口类用于流式查询,这个接口继承了 java.io.Closeable 和 java.lang.Iterable 接口,由此可知:
1、 Cursor 是可关闭的;2、 Cursor 是可遍历的。除此之外,Cursor 还提供了三个方法:
1、 isOpen():用于在取数据之前判断 Cursor 对象是否是打开状态。只有当打开时 Cursor 才能取数据;
2、 isConsumed():用于判断查询结果是否全部取完。
3、 getCurrentIndex():返回已经获取了多少条数据
因为 Cursor 实现了迭代器接口,因此在实际使用当中,从 Cursor 取数据非常简单:
cursor.forEach(rowObject -> {…});
但构建 Cursor 的过程不简单
我们举个实际例子。下面是一个 Mapper 类:

方法 scan() 是一个非常简单的查询。通过指定 Mapper 方法的返回值为 Cursor 类型,MyBatis 就知道这个查询方法一个流式查询。然后我们再写一个 SpringMVC Controller 方法来调用 Mapper(无关的代码已经省略):

上面的代码中,fooMapper 是 @Autowired 进来的。注释 1 处调用 scan 方法,得到 Cursor 对象并保证它能最后关闭;2 处则是从 cursor 中取数据。上面的代码看上去没什么问题,但是执行 scanFoo0() 时会报错:
java.lang.IllegalStateException: A Cursoris already closed.
这是因为我们前面说了在取数据的过程中需要保持数据库连接,而 Mapper 方法通常在执行完后连接就关闭了,因此 Cusor 也一并关闭了。所以,解决这个问题的思路不复杂,保持数据库连接打开即可。我们至少有三种方案可选。
方案一:SqlSessionFactory
我们可以用 SqlSessionFactory 来手工打开数据库连接,将 Controller 方法修改如下:
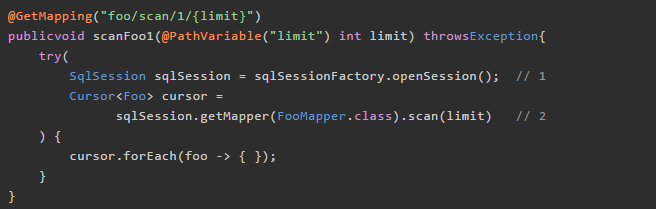
上面的代码中,1 处我们开启了一个 SqlSession (实际上也代表了一个数据库连接),并保证它最后能关闭;2 处我们使用 SqlSession 来获得 Mapper 对象。这样才能保证得到的 Cursor 对象是打开状态的。
方案二:TransactionTemplate
在 Spring 中,我们可以用 TransactionTemplate 来执行一个数据库事务,这个过程中数据库连接同样是打开的。代码如下:
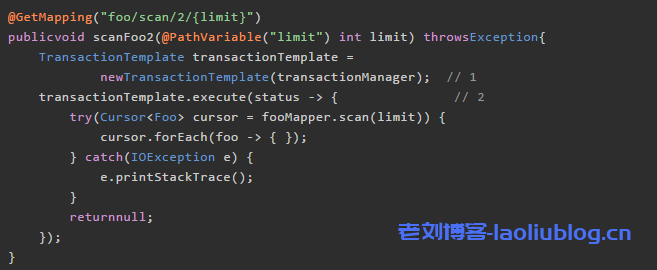
上面的代码中,1 处我们创建了一个 TransactionTemplate 对象(此处 transactionManager 是怎么来的不用多解释,本文假设读者对 Spring 数据库事务的使用比较熟悉了)。2 处执行数据库事务,而数据库事务的内容则是调用 Mapper 对象的流式查询。注意这里的 Mapper 对象无需通过 SqlSession 创建。
方案三:@Transactional 注解
这个本质上和方案二一样,代码如下:
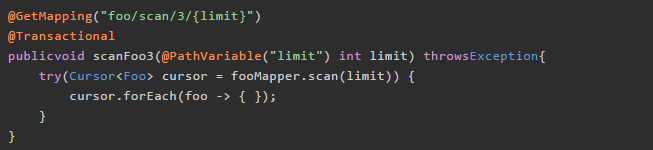
它仅仅是在原来方法上面加了个 @Transactional 注解。这个方案看上去最简洁,但请注意 Spring 框架当中注解使用的坑:只在外部调用时生效。在当前类中调用这个方法,依旧会报错。
以上是三种实现 MyBatis 流式查询的方法。